I keep running out of songs to listen to, and unfortunately, I don’t have as much time as I used to for sitting down for long hours, listening to random music, and adding to my playlists. During the lockdown, I created over 100 playlists, each with a specific theme or vibe. Now, it’s not entirely possible for me to explore and add songs to those playlists because I’ve forgotten the criteria I used for adding songs.
These days, I end up liking songs with the intention of coming back to them later. However, I’ve also found myself listening to the same songs I used to listen to a lot.
Every year, Spotify releases a Wrapped playlist that contains your 100 most-played songs. I now have six of these Wrapped playlists, with songs from 2018 to 2023. However, I don’t like all of the songs in these playlists. I want to be able to quickly go through multiple songs in a short amount of time to find and play the ones I actually enjoy.
This isn’t a major problem in my life, but I decided to fix it by building YourTopSongs. I know it should have been MyTopSongs, but I’ll change it later sometime in the future, if god’s willing.
Preparing Data
Since Spotify API doesn’t provide a way to interact with content of Wrapped, and my need involved everything related to the yearly wrapped, the best way I could think of is to use Spotipy, and go through all the playlists and scrape the content of playlists whose name starts with “Your Top Song ”
while True:
playlists = sp.current_user_playlists(limit=limit, offset=offset)
for playlist in playlists['items']:
if playlist['name'].startswith('Your Top Songs '):
playlist_name = playlist['name']
playlist_id = playlist['id']
# do iterations and save data as JSON
Initially, I saved the data as JSON, but needed the CSV in case I do some analysis on my data.
tracks_list = []
for playlist in data:
for track in playlist['tracks']:
track_info = {
# key: value
}
tracks_list.append(track_info)
df = pd.DataFrame(tracks_list)
df.to_csv('../data/wrapped.csv', index=False)
Output —
Roadmap
The idea is not complicated, and using the JSON file I have, I want my web app to do the following:
- Show 25 songs on the initial load.
- Allow one-click shuffling to display another set of 25 songs.
- Enable clicking/hovering on a song to play its preview.
- Option to open the song on Spotify if I like the preview and want to listen to the whole song.
Frontend
I then built the frontend in plain HTML, CSS, and JavaScript. I had to do some iterations and remove a bunch of useless features I added because I was getting distracted from what I actually wanted to build. After hours of tweaking, I got the desired frontend —
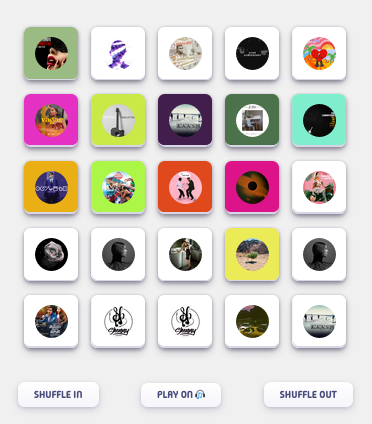
By this time, I had finalized everything. I was able to play the preview of the songs I as hovering on, but I was facing some issues — some songs’ preview was not available.
Song Preview ft Spotify API
At first, I decided to use the Spotify API for playing the song previews. However, I encountered an issue: hovering over a few songs was throwing error because preview_url field was null.
Decided to check the response for one of the songs, and found out that "IN" is missing from available_markets and the preview_url is also set to null.
$ curl --request GET \
--url https://api.spotify.com/v1/tracks/3e21cX0CVwzkQXiHz7WUQZ \
--header 'Authorization: Bearer BQBY7d...9gA&' | jq
sample response —
{
"available_markets": [
"CA",
"MX",
"US"
],
"name": "Drop The World",
"preview_url": null,
}
Looks like the rights to offer a preview of certain tracks can vary by country, and Spotify might only provide preview URLs for regions where they have the necessary permissions. Possibly? In any case, it was a bummer, so I had to figure it out anyway.
Checks
I wrote another piece of code that tests if the songs in my wrapped.csv file have the field preview_url. Based on the numbers, it would take ~10 minutes to test all the songs because I had 600 songs, and I’d be sending 600 requests, one-by-one. Using concurrent.futures for parallel requests saved time, but I ended up encountering…
{
"error": {
"status": 429,
"message": "API rate limit exceeded"
}
}
It’s always good to Backoff and Retry, which I did, and when the task was successfully complete, I found that there were 121 out of 600 songs that didn’t have a preview_url, which means no more 30 seconds of catchiness. Sad. It’s a big number considering the total number of songs.
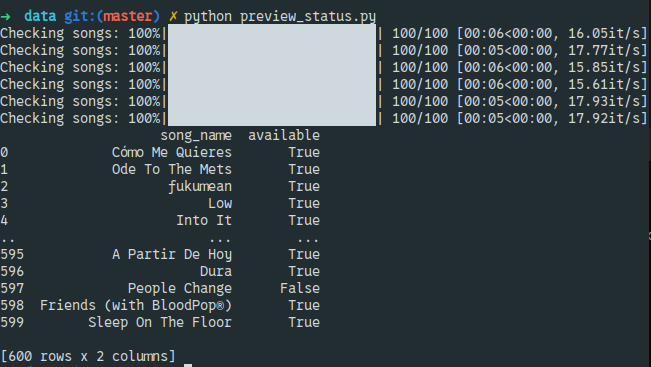
Anyway, I could have just avoided this step and worked on the solution instead, but I love getting distracted. Just kidding. I think this was important. So, what did I find out? I can’t say much apart from those damn 121 songs that I couldn’t play when I hover over them using my mouse or play them on my phone by putting my fat thumb on the small squared divs.
Going Back
Despite calling the previous step “avoidable”, it helped me figure out something. There were songs in the list of 121 songs that I had added to my old site previously. Spotify allows you to embed the song, and if you aren’t logged in, they let you play 30 seconds of the music. Interesting.
So, the logic is — I can get the 30-second-gist of the song through the embed, even through preview_url is null in the track’s response. What’s the purpose behind this? I don’s know.
If you open the Network tab and play this song, you’ll see —
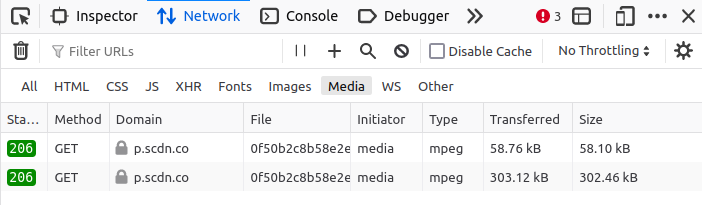
Just double click on the URL and you’ll have a new tab opened with the preview playing. So far, so good!
Then I just curled the embed URL and greped to search for any occurrences of mp3 within the content. Fortunately, I found it. You can also hit Ctrl+U, but I’m a frequent user of curl —
$ curl https://open.spotify.com/embed/track/77q65VGEbRnJlnX50UfnZS | grep -i mp3
"audioPreview":{"url":"https://p.scdn.co/mp3-preview/0f50b2c8b58e2e2bbc8eed152fc3d30ce8589b9c"}
Great Success!
Unnecessary Step
I also wanted to know, on an average, how many unplayable songs can appear on each shuffle.
- Total songs (
X): 600 - Unplayable songs (
Y): 121 - Songs per load (
Z): 25
The probability of picking an unplayable song during each load is — \[ P(\text{unplayable}) = \frac{Y}{X} = \frac{121}{600} = 0.201 \]
The expected number of unplayable songs in a 25-song load is the product of the probability of picking an unplayable song and the number of songs per load —
\[ \text{Expected number of unplayable songs} = 25 (Z) \times P(\text{unplayable}) \]
So,
\[ \text{Expected number of unplayable songs} \approx 25 \times 0.201 \]
\[ \approx 5.025 \]
So, on average, I can expect about 5 unplayable songs to appear in each 25-song load, which is fairly accurate. I don’t know if I did the calculations right!
Ditching Access Tokens
Before finding out the embed workground, I was simply pulling preview_url from the track’s JSON response -
async function getPreviewUrl(trackUrl) {
try {
const trackId = trackUrl.split('/').pop();
const response = await fetch(`https://api.spotify.com/v1/tracks/${trackId}`, {
headers: {
Authorization: `Bearer ${accessToken}`,
},
});
const data = await response.json();
if (data.preview_url) {
return data.preview_url;
}
}
}
I then decided to write a tiny Flask backend that would fetch the prview_url of any of the tracks I’m hovering on -
@app.route('/preview-url/<trackId>')
def get_preview_url(trackId):
try:
embedUrl = f"https://open.spotify.com/embed/track/{trackId}"
embedResponse = requests.get(embedUrl)
embedText = embedResponse.text
previewUrl = embedText.split('"audioPreview":{"url":')[1].split('"},"hasVideo"')[0]
return jsonify({'previewUrl': previewUrl})
Now, when I -
$ curl http://localhost:5000/preview-url/2m2ZGfJcs3lHWNPzhWH3XH | jq
I get -
{
"previewUrl": "https://p.scdn.co/mp3-preview/1d626aac6499d4867c9f800dfbafcca9d7b54d2f"
}
The good thing is, it would work for all the tracks because I don’t know if there’s any track available which Spotify doesn’t allow you to embed.
A tiny change in the getPreviewUrl function and we’re good to go —
async function getPreviewUrl(trackUrl) {
try {
const trackId = trackUrl.split('/').pop();
const response = await fetch(`/preview-url/${trackId}`);
if (!response.ok) {
throw new Error('Error fetching preview URL.');
}
const data = await response.json();
const preview = data.previewUrl;
return preview;
}
}
Conclusión.
I had a fun time building this project. The frustrating part was the frontend, but it managed to look decent when I was done with it. The challenging part in terms of audio was preventing multiple audio tracks from overlapping because I wanted them to play on hover, and hovering over multiple tracks would play each of them together. The rest, I don’t remember. Adios.
![]() You can check the live version here and source code on GitHub.
You can check the live version here and source code on GitHub.